
Loading Data from Amazon S3 into PySpark DataFrames using AWS Glue
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
Introduction
Hello, I'm Hemanth from the Alliance Department. In this blog, I will walk you through the process of loading data from Amazon S3 into PySpark DataFrames using AWS Glue. This process is essential for anyone working with data pipelines in the cloud, as it combines S3's storage capabilities with PySpark's data processing power in a fully managed environment.
AWS
Amazon Web Services, or AWS, is a cloud service platform that provides content distribution, database storage, processing capacity, and other features to support corporate expansion. AWS has offered a broad range of services in many different categories, including Compute, Storage, Networking, Database, Management Tools, and Security.
S3
Simple and popular AWS Service for storage. Replicates data by default across multiple facilities. It charges per usage. It is deeply integrated with AWS Services. Buckets are logical storage units. Objects are data added to the bucket. S3 has a storage class on object level which can save money by moving less frequently accessed objects to a colder storage class.
AWS Glue
One fully managed ETL (Extract, Transform, Load) solution that simplifies the process of preparing and loading data for analytics is AWS Glue. With the help of Glue, users may extract data from many sources, transform it with a range of tools, and then put it into a destination like a data lake or warehouse, streamlining the ETL process.
Demo
Navigate to the S3 service in the AWS Management Console. Click on Create Bucket.
Provide a unique name for your bucket and leave the remaining options as default. Click Create Bucket.
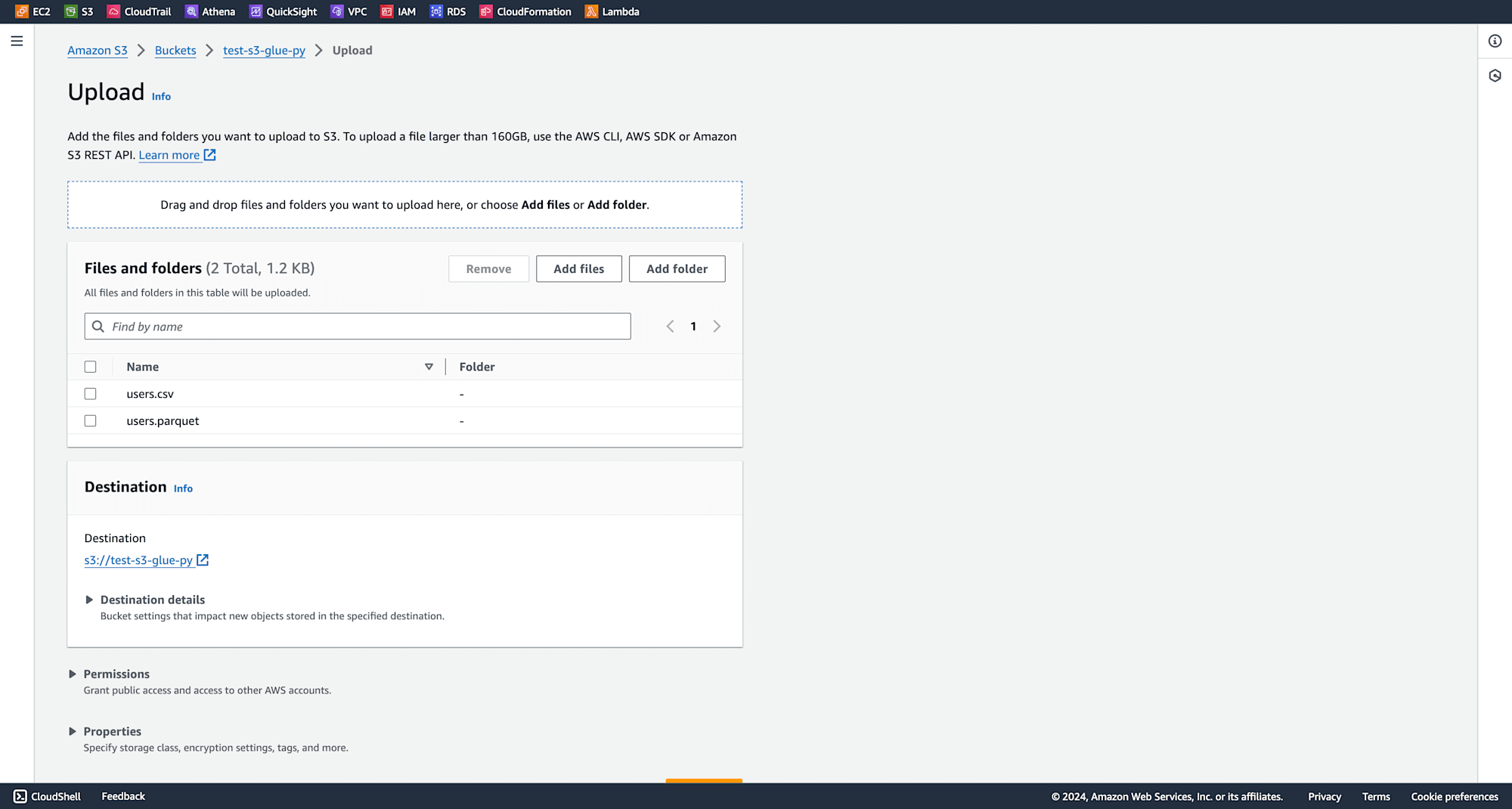
Once the bucket is created, upload the files that you intend to load into PySpark.
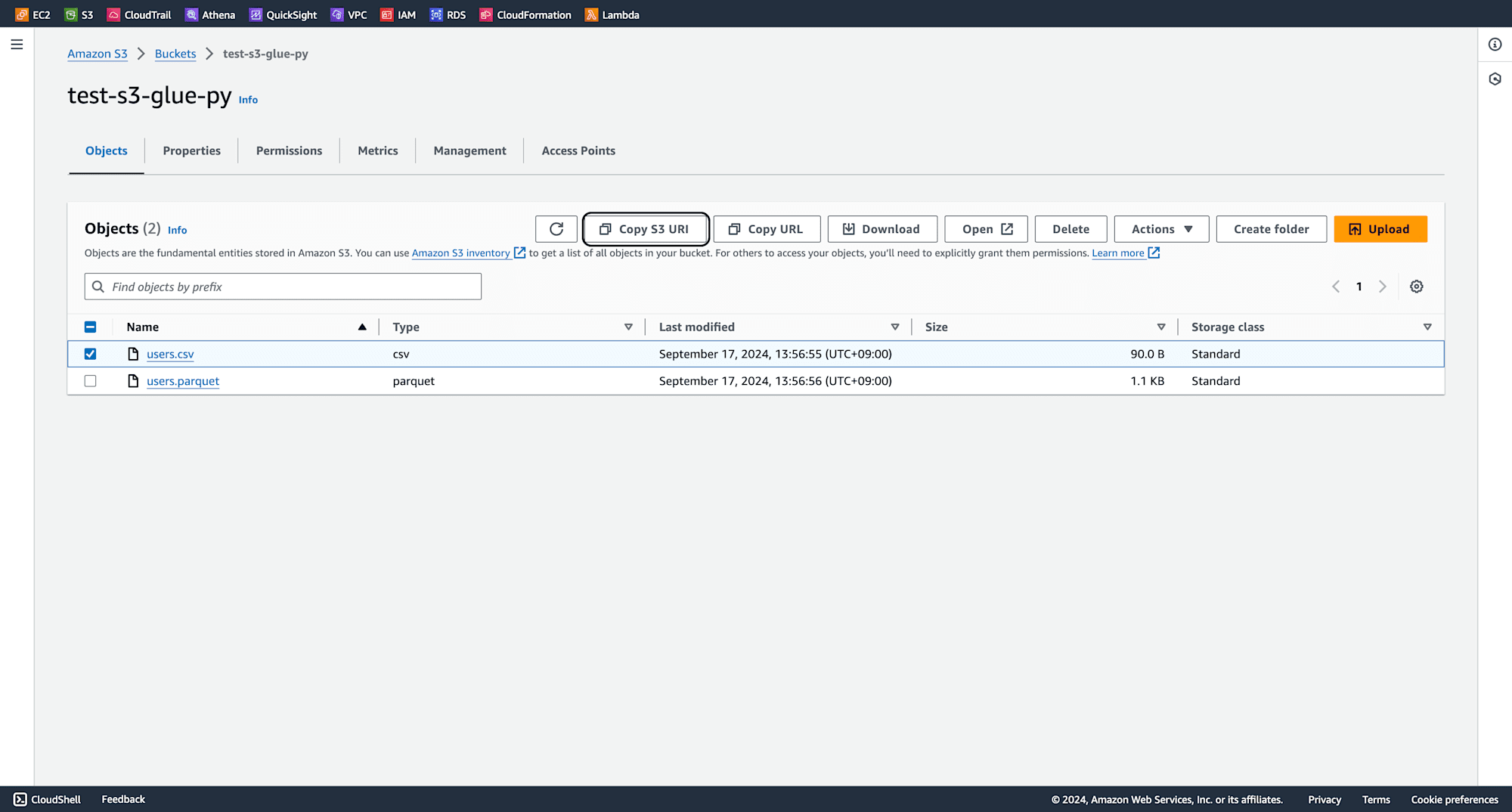
Copy the S3 URI of these files for the Glue job later.
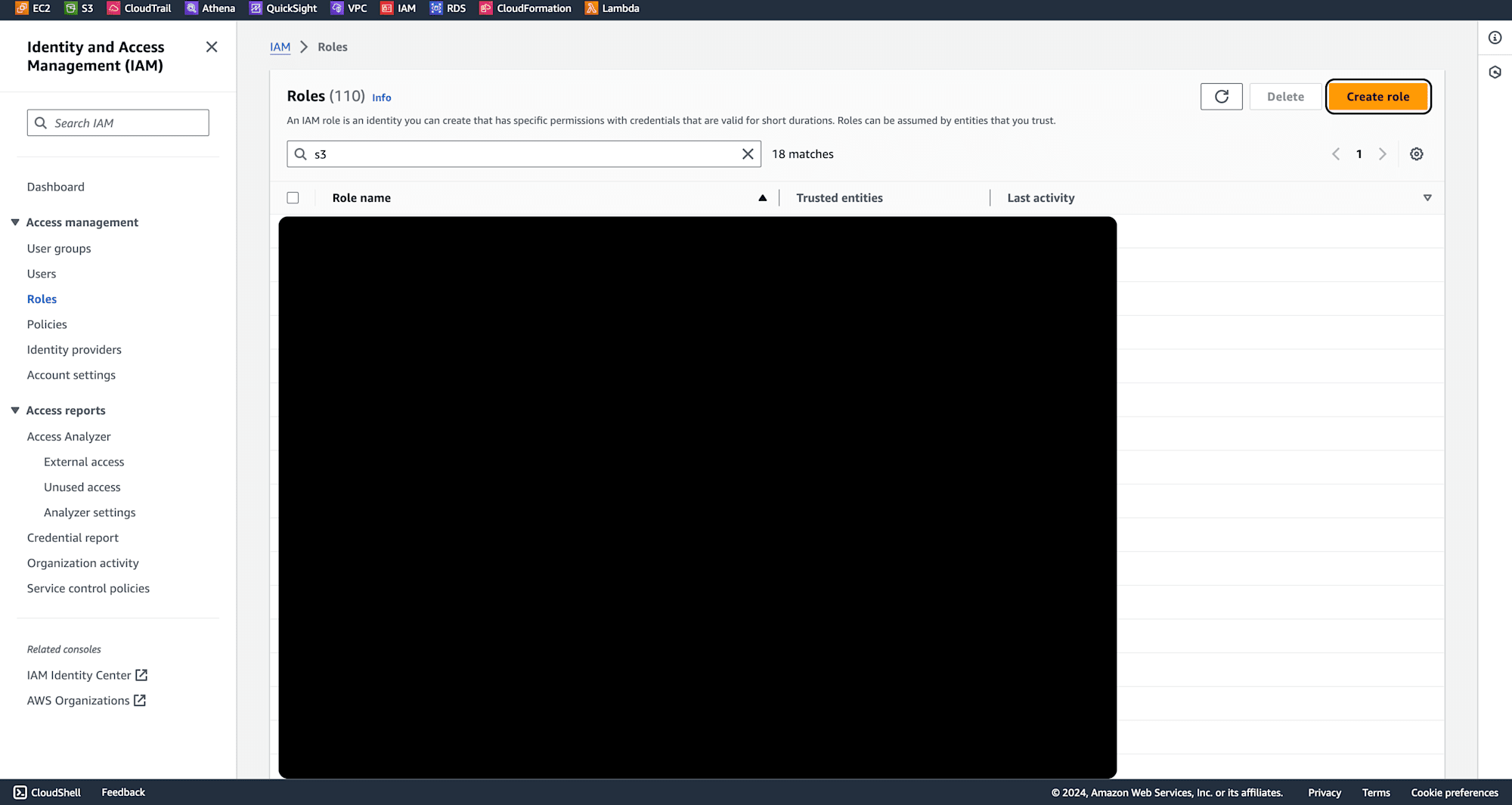
Navigate to IAM from the Management Console and click Create Role.
Select Glue as the service that will use this role, and click Next.
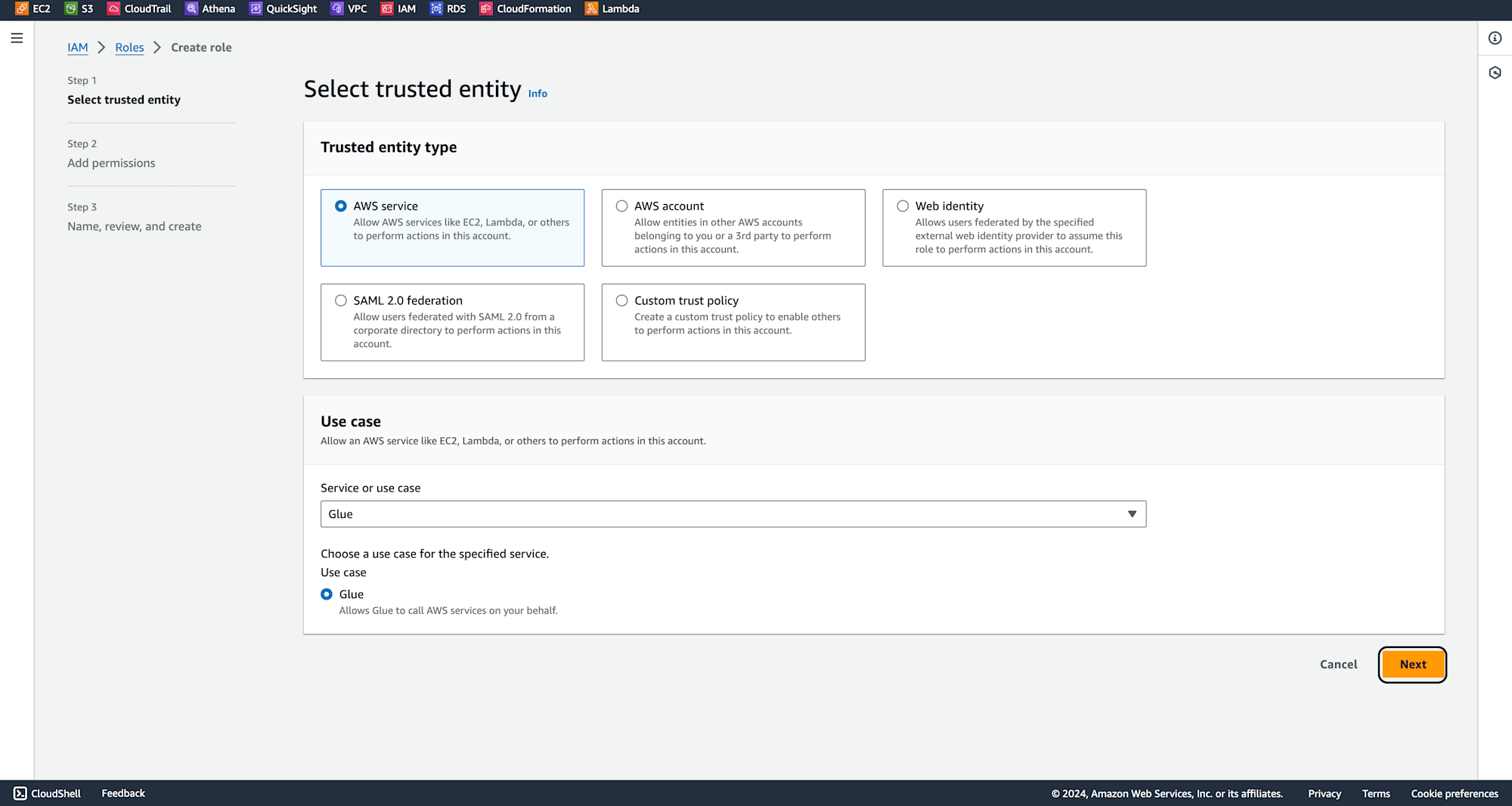
Add the necessary permissions, including:

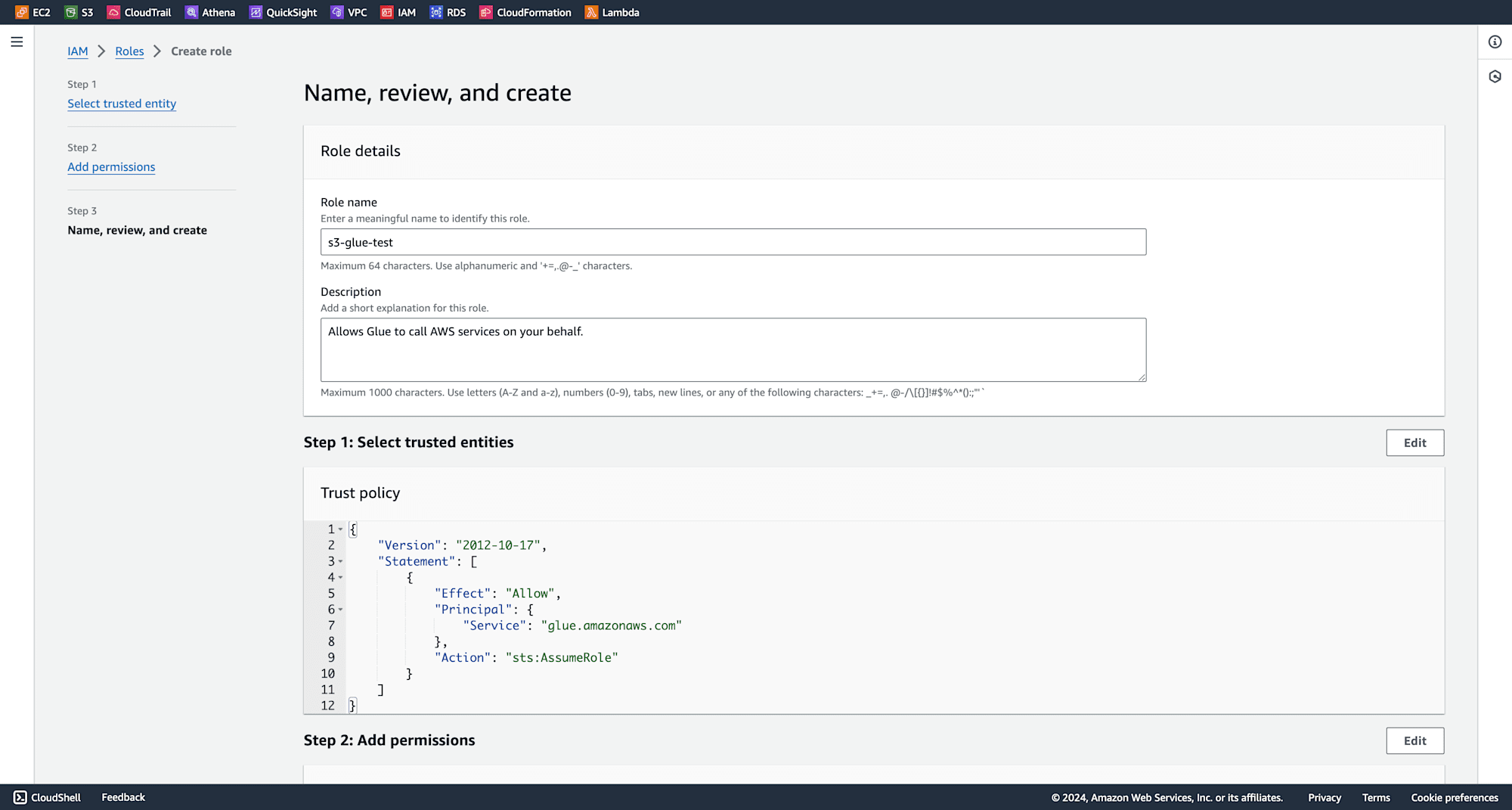
Then give a rule name and click create role.
In the AWS Glue dashboard, navigate to ETL Jobs and click on Script Editor.
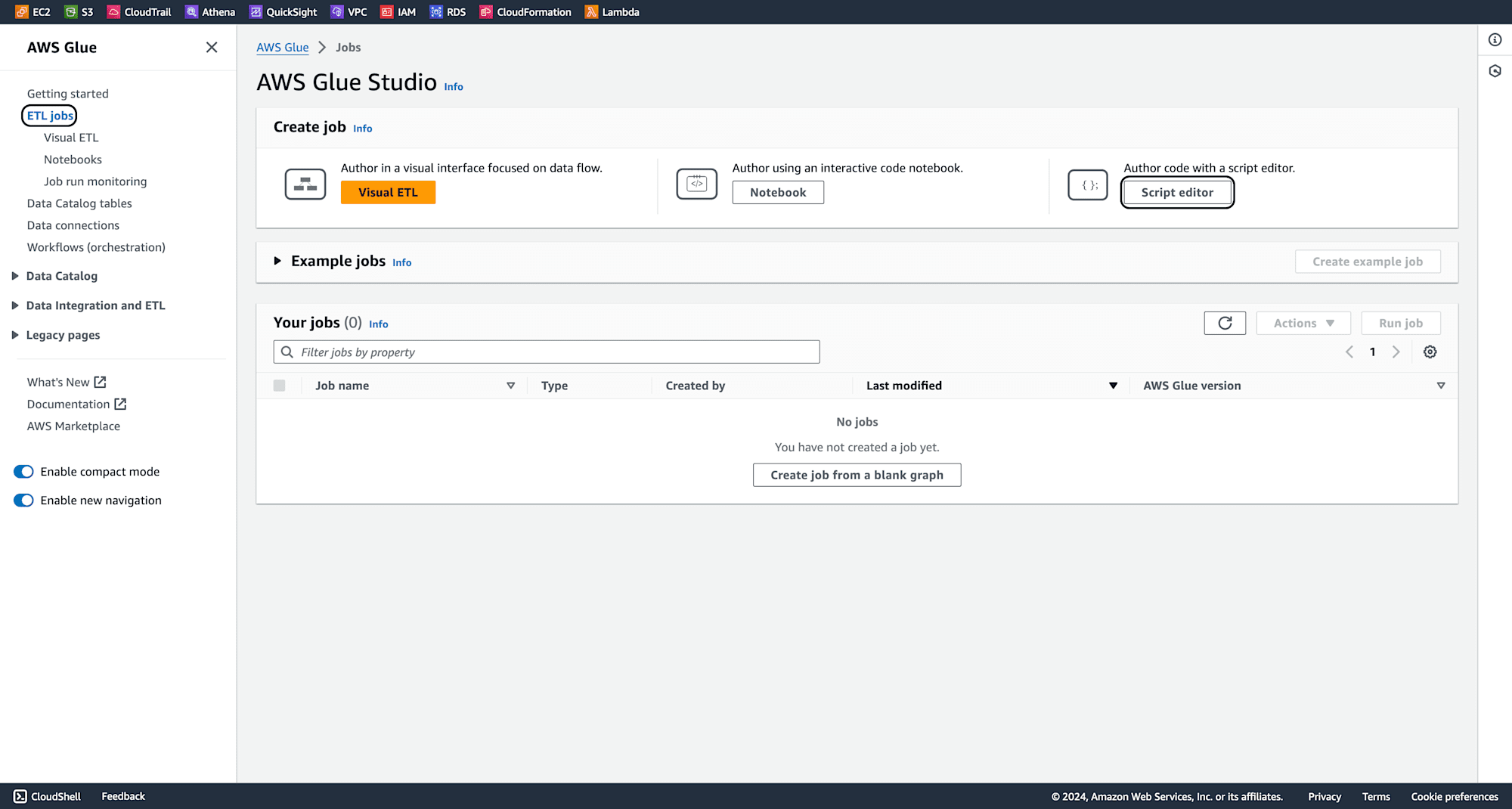
Click on Create script.
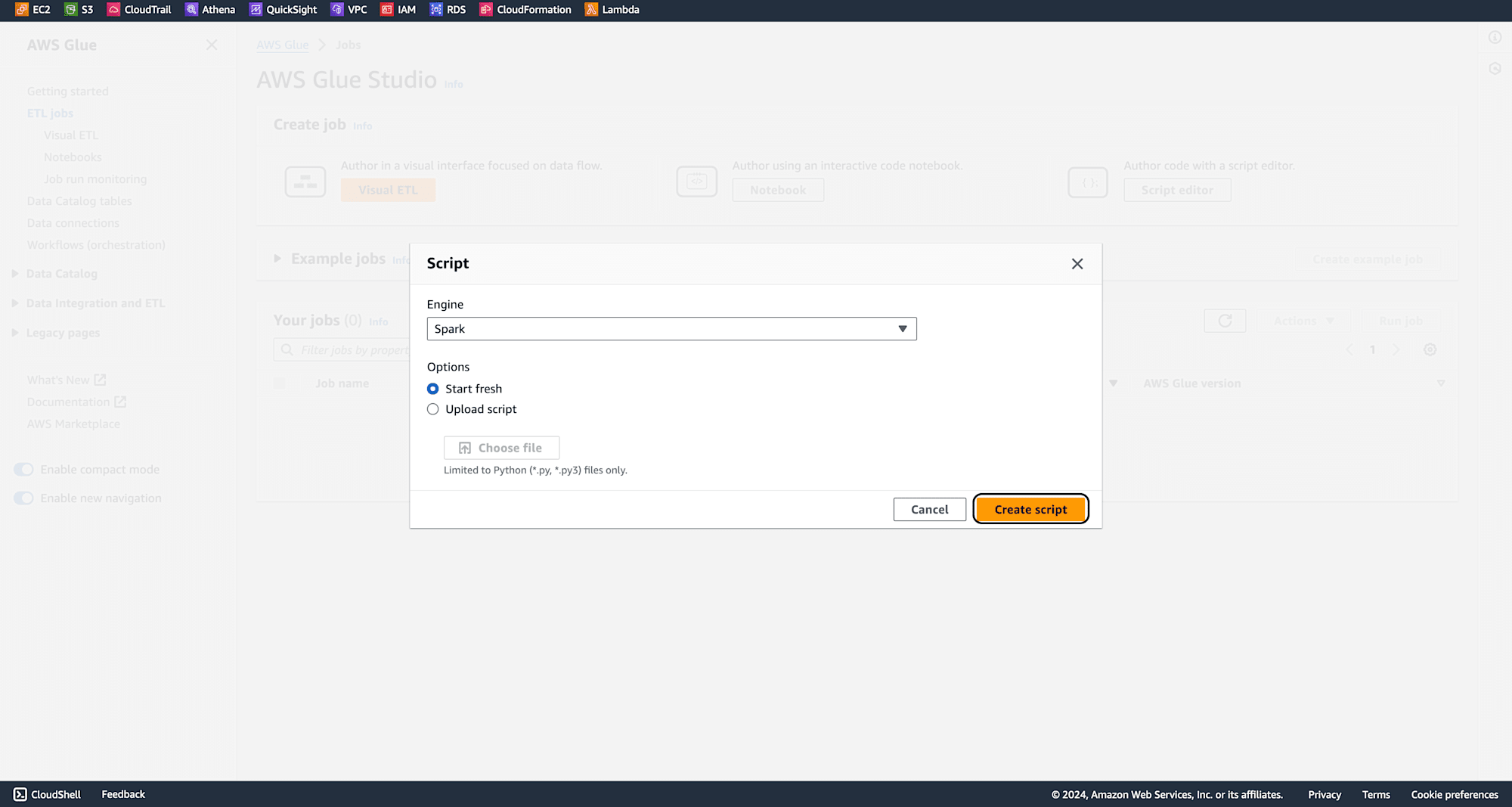
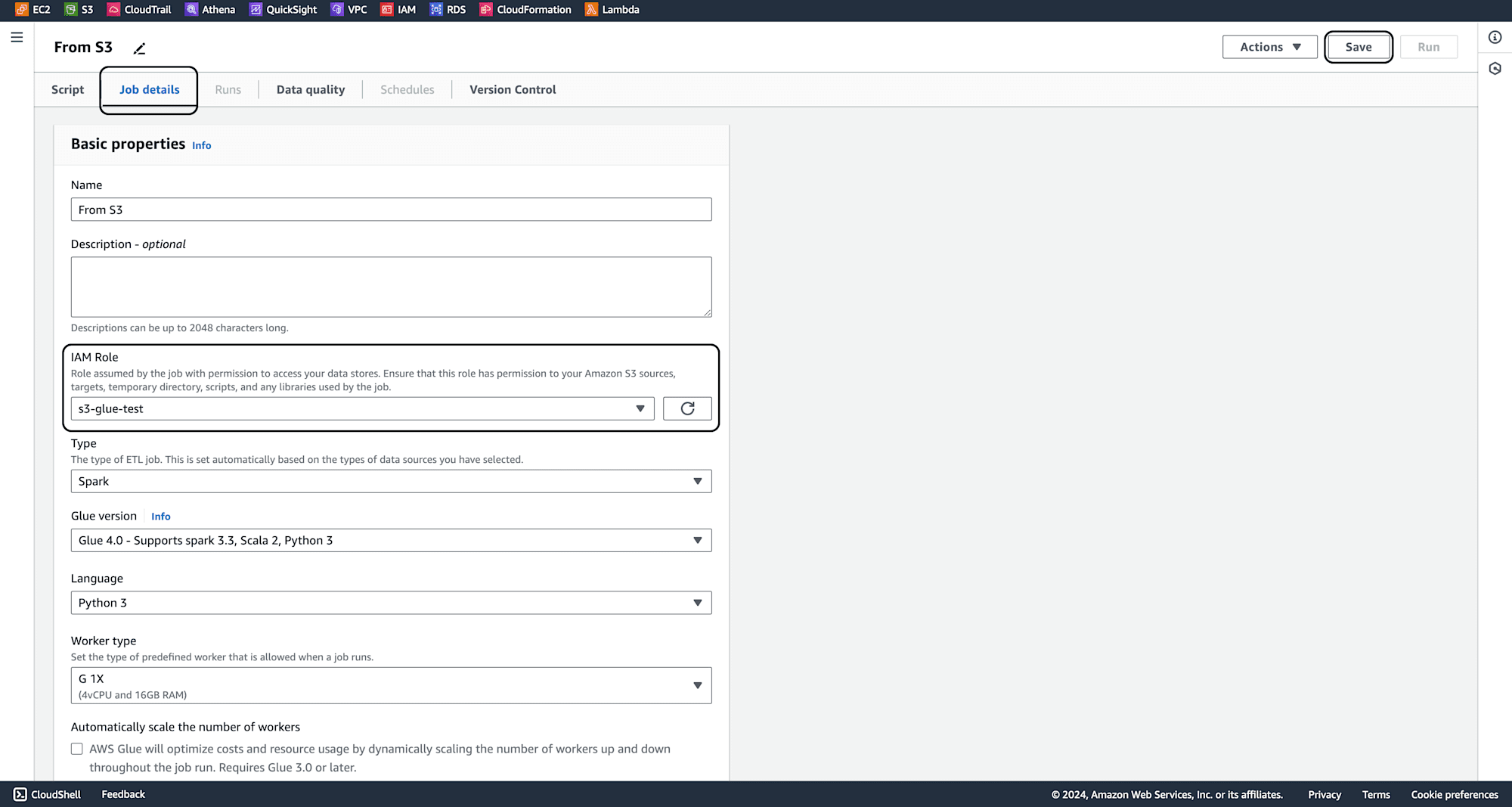
Provide a meaningful name for the job and In the Job Details section, select the IAM role created earlier. Click Save.
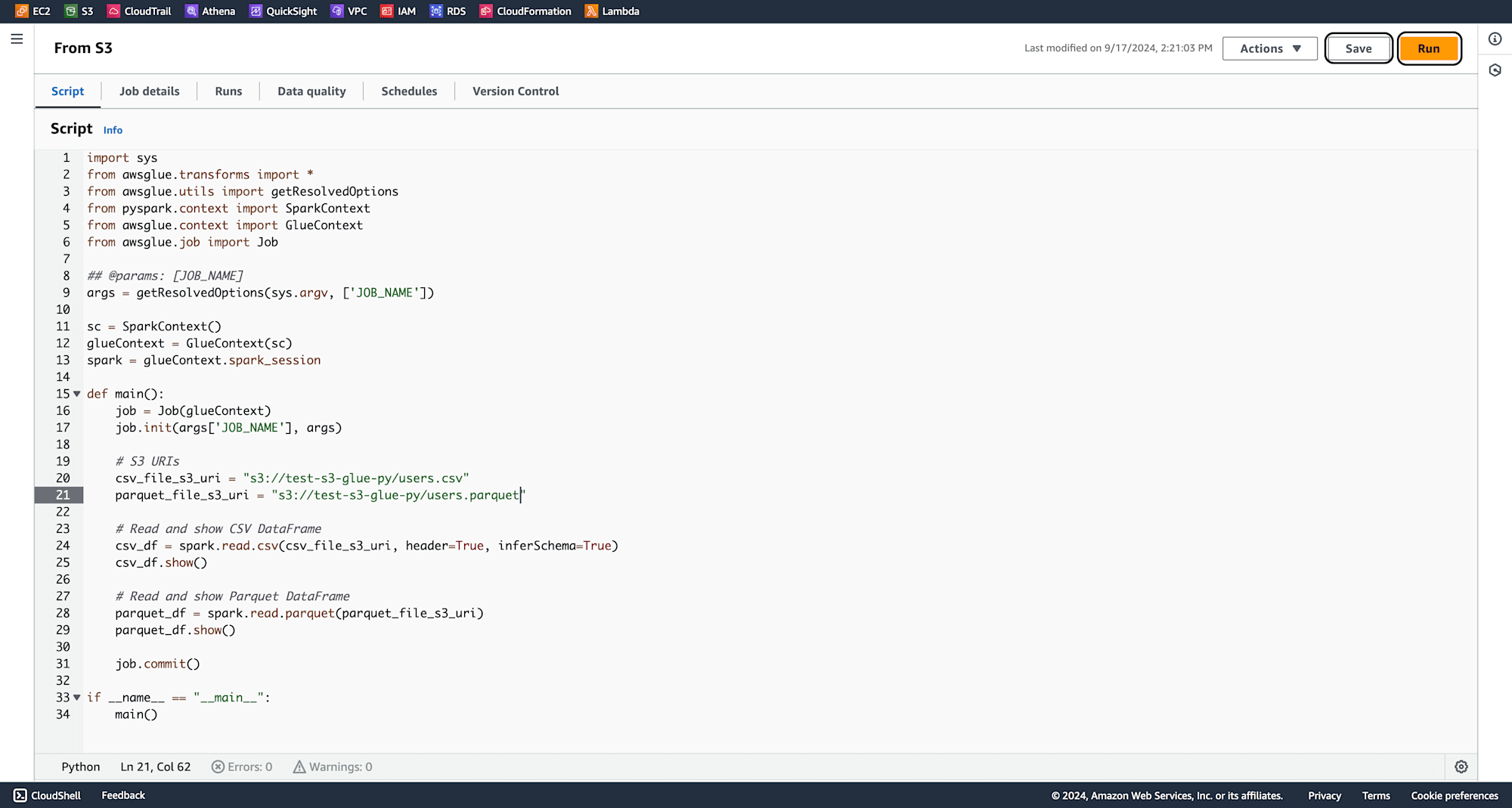
Under the Script section, paste the PySpark code that reads data from the S3 bucket and loads it into a DataFrame. Use the S3 URI copied earlier in the code.
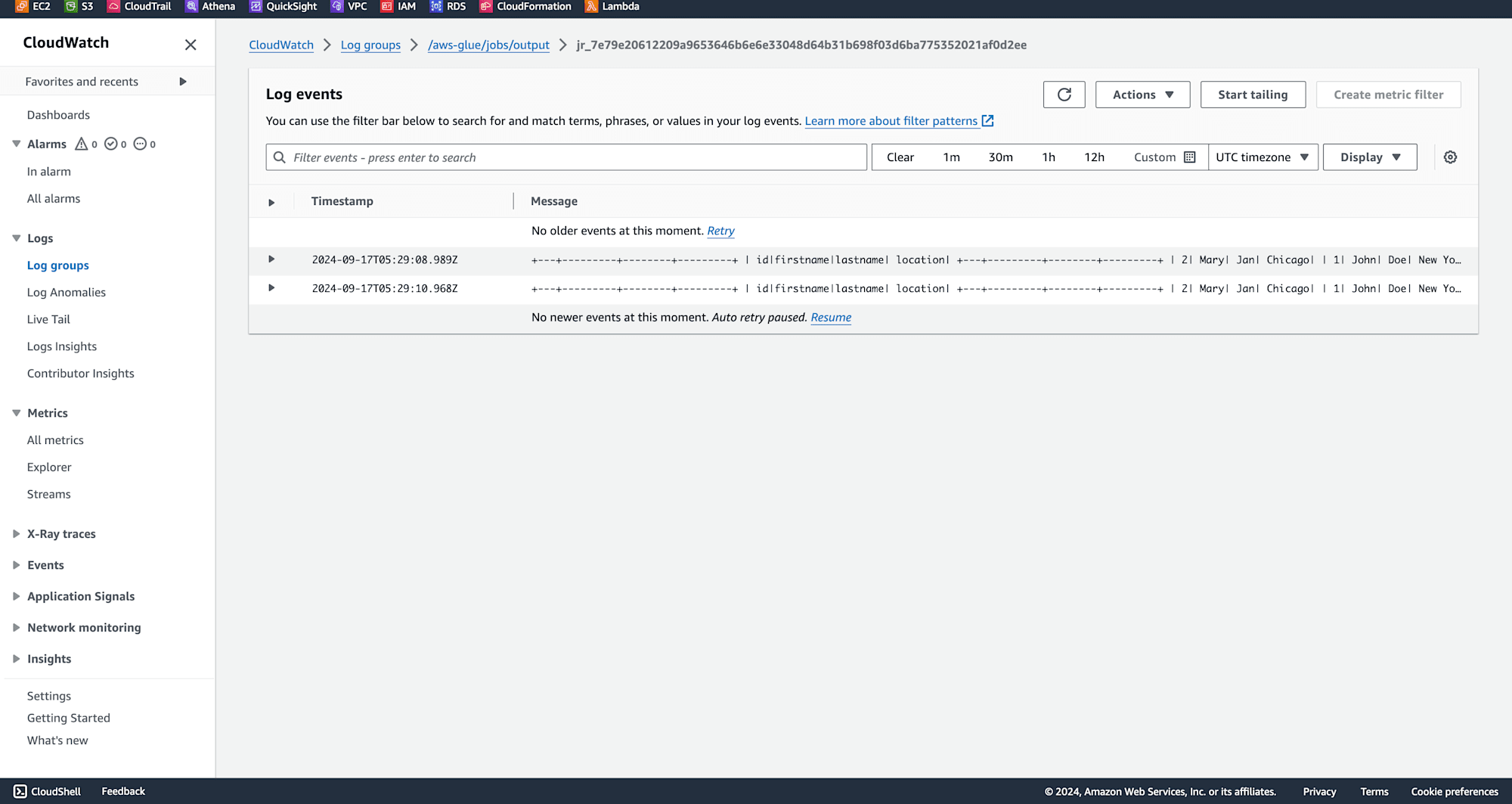
Click on run, and click on output logs once job running is successfull as shown below.
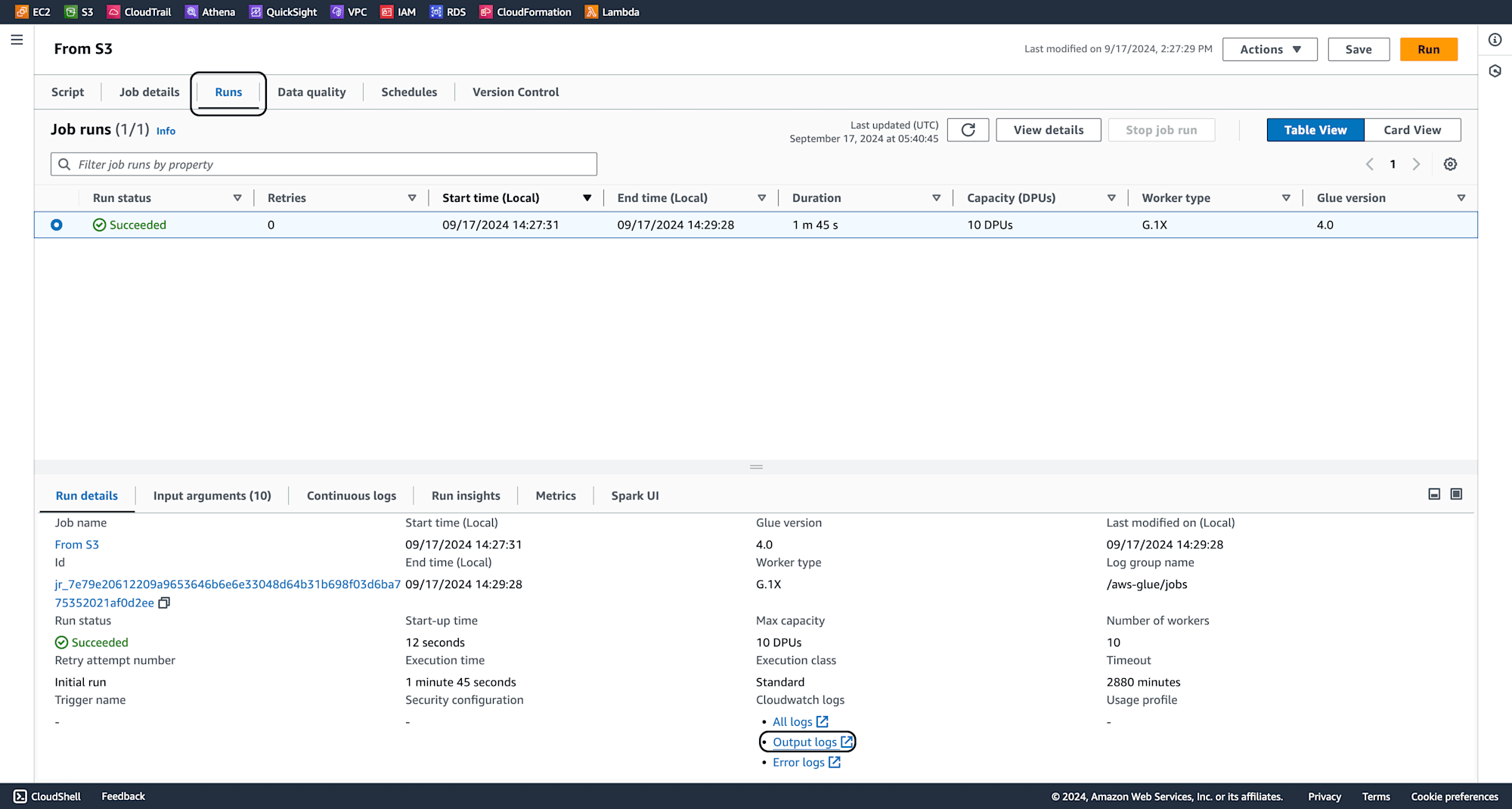
The output verifies that data has been succesfully read from S3 files to PySparkDataframes.
Conclusion
By following this step-by-step guide, you have successfully learned how to load data from Amazon S3 into PySpark DataFrames using AWS Glue. This method offers a scalable and efficient way to handle large datasets in the cloud, leveraging the powerful combination of S3's storage capabilities and PySpark's data processing engine. AWS Glue simplifies the process, making it easier for data engineers and developers to build and maintain data pipelines.






